
EIP: Back to Fundamentals !
AI, LLM, ML, NLP, … Unless you’ve been living under a rock for the past two years, you’ve probably had your fill of these syntagma. As for me, I can’t read on this site, or anywhere else in the tech community, any IT post or article, without being bombarded with these acronyms, by an endless stream of self-proclaimed AI gurus. Everyone wants to demonstrate, through pages of listing, how to do RAG or MCP, all this such that, finally, to be able to ask a model stupid things like the first names of the four Beatles or what does a crocodile eat for the dinner.
In my opinion, there is currently a real overwhelming amount of AI hype and buzzword fatigue in the tech community. At such an extent that I felt a compelling need to return to fundamentals. And, in my case, these fundamentals where the EIP (Enterprise Integration Patterns). Accordingly, I searched my library for the Hohpe and Wolf black book, I removed the dust from its cover and I started to read it again, from the beginning to end.
I use to react to posts on this site recommending books, like Clean Architecture, published 8 years ago, which I consider outdated. It happened also to me recently to advice against Spring in Action, published initially in 2019 and currently in its 6th edition, dated 2022. So, this book has been published 6 times in 3 years ! Which wasn’t obviously enough to cover its full spectrum as it still lacks lots of topics.
Anyway, if I’m dwelling on this subject here, this is to say that I’m not really a big fan of old books because, in our field, things are changing so fast, for the best and for the worst. But this EIP book, published in 2003, is incredibly up to date.
So, after reading it again more than 20 years later, I thought that I definitely need to contribute somehow to promote these EIPs which, in my opinion, represent the most important foundation of the software industry. And the only way I found to contribute is to provide sui generis implementations of these EIPs.
But once this decision taken, the difficulty of the technology-agnostic requirement of such implementations appears immediately. How to implement these patterns without getting bound to any technology or product ? As the book’s authors state in its preface, they would have been tempted to provide implementations as well but, given the wide diversity of the suitable products and technologies, the book would have been “likely to never finish or else to be published so late as to be irrelevant”.
It’s valuable to see the authors’ concern to avoid a possible irrelevance of their work, due to a too late publishing date, but they may be at ease that this isn’t the case, even today, more than 20 years after. And since, in any case, a technology-agnostic implementation would be neither possible, nor useful, I choose the one and only Java based enterprise grade integration platform: Apache Camel.
This having beed said, I’m planning to take, one by one, most of the EIPs in the Hohpe and Wolf book and to implement them, using Apache Camel and its Quarkus extensions. And while I’m at it, I’ll try to find credible and realistic use cases, extracted from my daily experience with enterprise grade applications, far from the “hello world” residual examples. I’m not sure how useful my approach might be, but I really need to contribute to this foundation, if only in the most modest way possible.
The Hohpe and Wolf book is organized in a very systematical and methodical way, based on the patterns classifications. But I won’t follow the same approach. Instead, I’m proceeding in alphabetical order. And since the first pattern, in the alphabetical order, is the aggregator,I’m starting with it. This might not seem to be a very pedagogical approach as the aggregator is probably one of the most complex patterns and the professional practice is to start from simple to complex, not the other way around. But having gone through the book, from beginning to end, is one of the pre-requisites here, accordingly, I thought that the patterns order isn’t essential.
As you’ll see, each pattern implementation is documented by its associated README.md file, observing the same template. This template consists in the following paragraphs:
- Scenario: this is a short description of the business case chosen to illustrate the pattern.
- Architecture: the software architecture, i.e. the libraries, the frameworks, the dependencies, the extensions, etc. if any, required by the implementation.
- Flow: a simple graphical sketch of the use case showing the involved components in a similar way to a sequence diagram.
- Key components: description of the most important components and their role.
- Business value: optional.
- Test and run: full instructions guiding how to test and run the case.
So, let’s start !
The Aggregator
This project demonstrates Apache Camel’s Splitter and Aggregator patterns using a realistic e-commerce scenario.
Scenario
An e-commerce platform processes orders that contain items from multiple suppliers. The system:
- Splits orders into individual items
- Aggregates items by supplier and shipping address to optimize shipments
- Creates consolidated shipments for cost efficiency
Architecture
The diagram below shows the software architecture of the implementation.

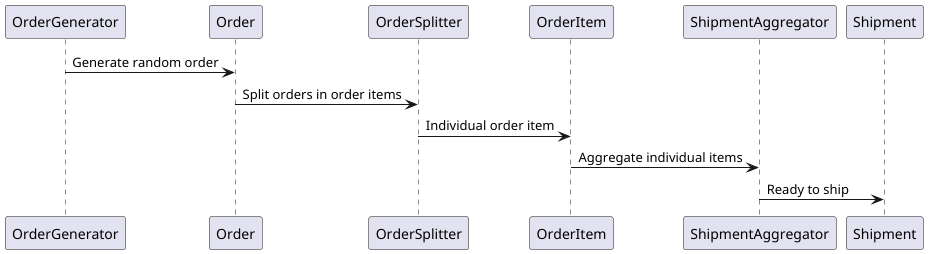
Everything starts with the OrderGenerator processor which generates random test
orders. These orders are instances of the Order record. They are generated on
time based frequency, one every 10 seconds, using the timer Camel component.
Once generated, each order is split in a list of its corresponding OrderItem
instances, by the OrderSplitter Camel processor. After which, the individual
OrderItem instances are aggregated, based on their supplier ID and shipping
address, into instances of Shipment. This is the role of the ShipmentAggregator
Camel processor which defines the aggregation strategy.
Last but not least, the Shipment instances, ready to be delivered, are just
printed out in the Camel log file. In a real case, of course, they would have
been sent to a delivery channel.
Flow
The following sequence diagram is illustrating the implementation’s flow:
Key Components
- OrderSplitter: Breaks orders into individual items with context
- ShipmentAggregator: Groups items by supplier + shipping address
- OrderGenerator: Creates realistic sample orders
The OrderSplitter class implements the Processor Camel interface and, in
its process(Exchange exchange) method, it splits an Order instance, passed as
an input message, to its corresponding OrderItem instances list.
Here is the source code:
@ApplicationScoped
@Named("orderSplitter")
public class OrderSplitter implements Processor
{
@Override
public void process(Exchange exchange) throws Exception
{
Order order = exchange.getIn().getBody(Order.class);
List<OrderItem> enrichedItems = order.items().stream()
.map(item -> item.withOrderContext(order.orderId(),
order.shippingAddress()))
.toList();
exchange.getIn().setBody(enrichedItems);
}
}
As for the ShipmentAggregator, it performs the complementary operation of
grouping the individual OrderItem instances, issued from the splitting process,
using an aggregation key which consist in the concatenation of the supplier ID
and the shipment address.
@ApplicationScoped
@Named("shipmentAggregator")
public class ShipmentAggregator implements AggregationStrategy
{
@Override
public Exchange aggregate(Exchange oldExchange, Exchange newExchange)
{
OrderItem newItem = newExchange.getIn().getBody(OrderItem.class);
@SuppressWarnings("unchecked")
List<OrderItem> items = Optional.ofNullable(oldExchange)
.map(ex -> (List<OrderItem>) ex.getIn().getBody(List.class))
.orElse(new ArrayList<>());
items.add(newItem);
Exchange exchange = Optional.ofNullable(oldExchange)
.orElse(newExchange);
exchange.getIn().setBody(items);
return exchange;
}
public Shipment createShipment(List<OrderItem> items)
{
return items.stream()
.findFirst()
.map(first -> new Shipment(first.supplierId(), first.shippingAddress(), items))
.orElse(null);
}
}
The code above accumulates OrderItems instances, having the same aggregation
key, into a single list. It accepts two input arguments:
- the
oldExchangewhich represents the current state accumulated from previous aggregations; it is null initially; - the
newExchangecontaining the incoming message;
The oldExchange argument is checked for the null value, i.e. no previous
accumulation exists and, then, a new item list is instantiated. Otherwise, if
the oldExchange isn’t null, then the list of the previously accumulated
OrderItem is extracted from it and the new OrderItem instance is added to
it from the newExchange argument.
Business Value
- Cost Reduction: Fewer shipments per supplier
- Efficiency: Consolidated deliveries
- Scalability: Handles multiple suppliers automatically
Running the Application
In order to run the application, perform the following steps:
$ git clone https://github.com/nicolasduminil/eip.git
$ cd eip
$ mvn package
$ java -jar aggregator/target/quarkus-app/quarkus-run.jar
Now the application is up and running. It will:
- Generate sample orders every 10 seconds
- Split orders by supplier
- Aggregate items into optimized shipments
- Log the entire process
The route labeled orderProcessing, which triggers the whole flow, is declared
with autoStartup(false) in the ECommerceRoute class. This means that it won’t
be started automatically but, in order to give you full control, it should be
handled via the Hawtio console. The following Maven dependency:
...
<dependency>
<groupId>io.hawt</groupId>
<artifactId>hawtio-quarkus</artifactId>
<version>4.4.1</version>
</dependency>
...
includes the Hawtio console in your application JAR. Then by fireing your prefered browser at http://localhost:8080/hawtio, you’ll see something similar to the picture below:
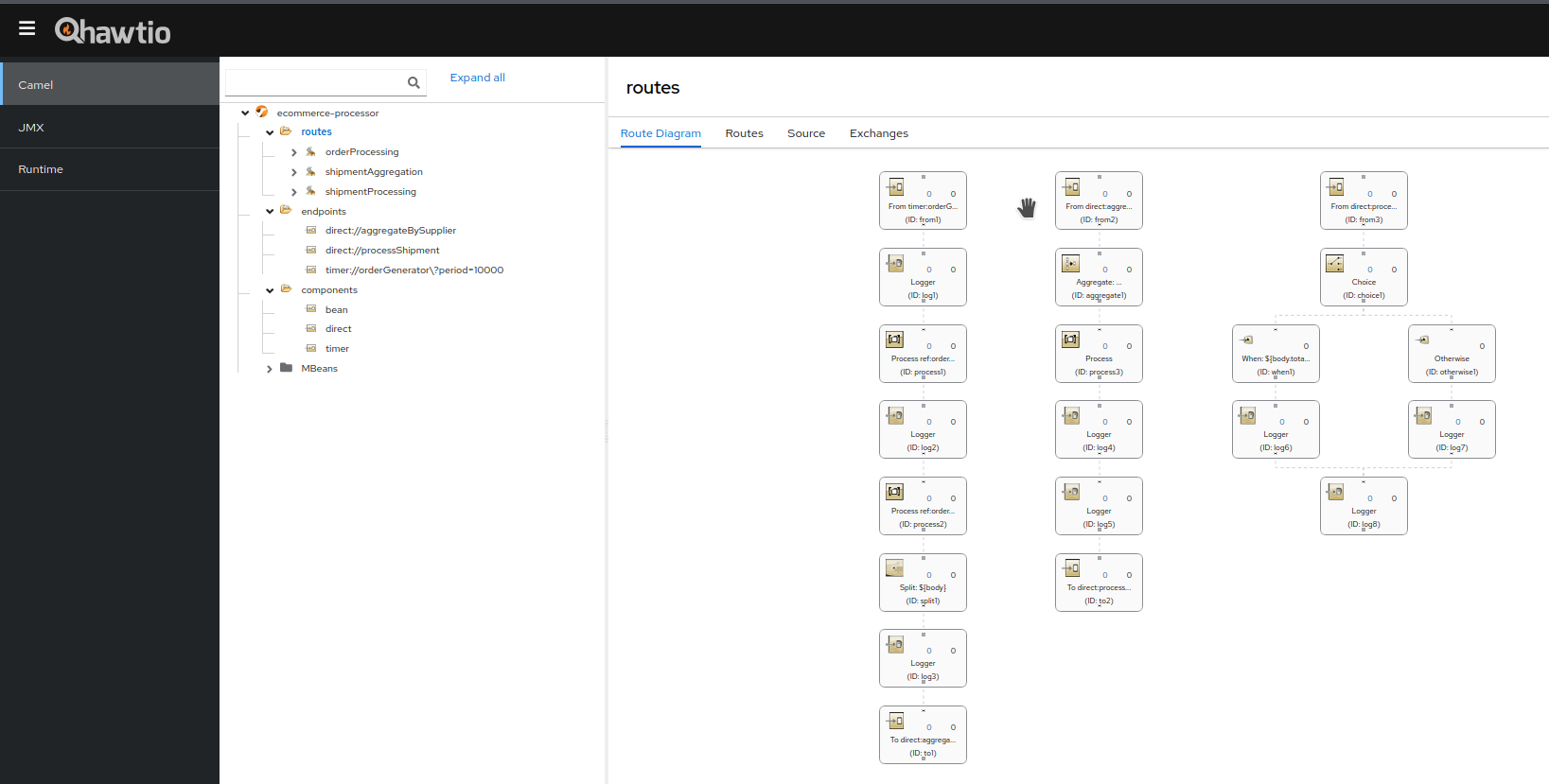
Now, go to Camel->Routes->orderProcessing and, in the right most pane, select
the tab labeled Operations. Then scrool down until you see the method
void start(). Unfold it and click the red button Execute. The message Operation
successful should be displayed and the route will start. You can tell that as
your Camel log file will show trace messages.
Executing the String getState() method will show that the route is active.
Whenever you think that you finished experiencing with th use case, you can
execute the method void stop() and the process will terminate. Don’t hesitate
to play with different operations exposed here, in the Hawtio console.
Sample Output
=== Processing new order ===
Generated order: Order{orderId='ORD-123', customerId='CUST-456', items=5}
Processing item: OrderItem{productId='LAPTOP-1', supplierId='SUPPLIER_ELECTRONICS', quantity=2}
=== SHIPMENT CREATED ===
Shipment: Shipment{id='SHIP-SUPPLIER_ELECTRONICS-123', supplier='SUPPLIER_ELECTRONICS', items=2, value=250.50}
HIGH VALUE shipment (250.50€) - Priority processing
Key Patterns Demonstrated
- Splitter Pattern:
split(body())breaks orders into items - Aggregator Pattern: Groups by
aggregationKey(supplier + address) - Content-Based Router: Routes high-value shipments differently
